Warum und wie müssen unstrukturierte Daten strukturiert werden?
Die Auswertung und Nutzung großer Datensammlungen gehört seit jeher zu den Kernkompetenzen erfolgreicher Versicherungsunternehmen. Wo früher intensive Auswertungsprojekte nötig waren, hält heute die Echtzeitanalyse Einzug. Jedoch liegen viele Daten nicht in einer verarbeitbaren, sprich strukturierten Form vor. Was bedeutet das überhaupt und was wird dagegen getan?

Die Auswertung und Nutzung großer Datensammlungen gehört seit jeher zu den Kernkompetenzen erfolgreicher Versicherungsunternehmen. Wo früher intensive Auswertungsprojekte nötig waren, hält heute die Echtzeitanalyse Einzug. Jedoch liegen viele Daten nicht in einer verarbeitbaren, sprich strukturierten Form vor. Was bedeutet das überhaupt und was wird dagegen getan?
Daten lassen sich grundsätzlich in strukturierte und unstrukturierte Daten unterscheiden. Die strukturierten Daten haben eine tabellenartige Form, sie besitzen beispielsweise einen Bezeichner und Werte für die jeweilige Tabellenspalte. Die Einträge der jeweiligen Spalte haben alle denselben Datentypen und enthalten immer gleichartige Information. Im untenstehenden Beispiel stehen in der Spalte „Prämie in Euro“ bspw. in jeder Zeile Zahlen, die die Prämie des jeweiligen Kunden widerspiegeln. Solche Daten lassen sich mit einem Computer sehr gut verarbeiten und analysieren.
Leider bilden strukturierte Daten nur einen geringen Teil der uns zur Verfügung stehenden Informationsquellen. Der größte Teil der Daten liegt hingegen unstrukturiert vor. Man schätzt, dass etwa 80 Prozent der täglich anfallenden Daten unstrukturiert sind. Warum ist das so? Die Weitergabe von Information geschieht von Mensch zu Mensch über die Sprache. Ganz gleich ob man einen Brief schreibt, eine WhatsApp versendet, eine Produktrezension bei Amazon erzeugt oder im Schulunterricht eine Frage des Lehrers beantwortet. Unsere Sprache dient als umfangreiches Weitergabe- und Codierungswerkzeug von Wissen und Informationen. Solche Daten haben eine sehr hohe Informationsdichte, die sich aber nur schwer automatisiert analysieren lässt. Um diese Daten nutzbar zu machen, muss im ersten Schritt eine Art Strukturierung erfolgen. Als Hilfsmittel verwendet man hier Text Analytics oder Text Mining.
Wie strukturiert man nun solche unstrukturierten Daten?
Schauen wir uns dazu ein erstes einfaches Beispiel an.
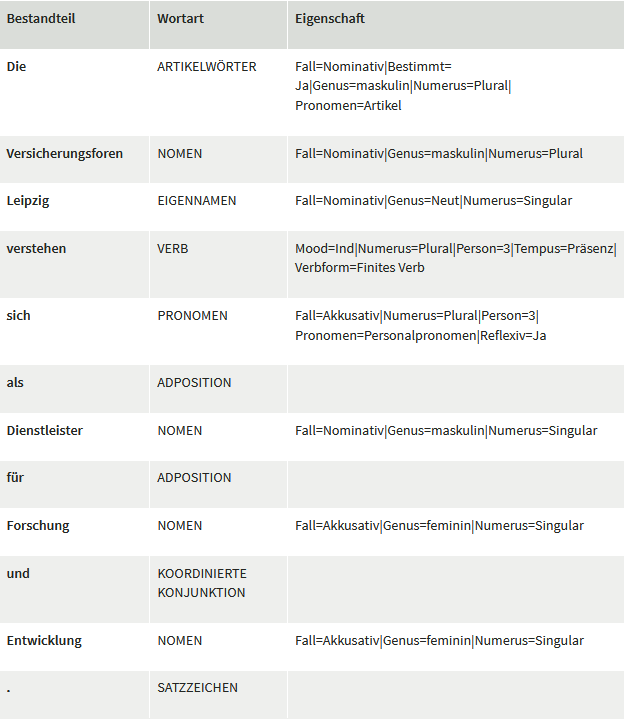
„Die Versicherungsforen Leipzig verstehen sich als Dienstleister für Forschung und Entwicklung.“
Für den Computer bildet dieser sogenannte String nur eine Aneinanderreihung verschiedener codierter Symbole. Für ihn ist somit keinerlei Struktur ersichtlich. Oder doch? Wie ist ein Mensch in der Lage, einen solchen Text zu verstehen? Hierfür wendet der Mensch alle Regeln an, die er über viele Jahre im Deutschunterricht in der Schule vermittelt bekam. Für den Computer schafft man es also nur, Struktur in die Sprache zu bekommen, indem man sie mit Natural Language Processing aufbereitet und ihm so eine Struktur erschafft. Dabei wird zum Beispiel ermittelt, was die einzelnen Wörter (Bestandteile) eines Satzes sind und welche grammatikalische Bedeutung (Wortart) sie haben – ist es ein finites Verb oder infinites Verb, ist es ein Substantiv, eine Präposition, ein Personalpronomen, in welcher Zeitform wurde der Text verfasst (Eigenschaften) etc. Sicher kommt Ihnen Einiges davon bekannt vor.
Aber wie ist ein Computer in der Lage, dies zu bestimmen? Hierfür bedient er sich der linguistischen Regeln und Methoden des Machine Learnings. Natürlich sind diese ersten Ergebnisse nicht frei von Fehlern, aber doch schon ziemlich beeindruckend. Mit diesen nun strukturierten Daten kann weitere Analytics angewandt werden. Die nachfolgende Tabelle zeigt bspw. die Ergebnisse, mittels UDPipe ( http://ufal.mff.cuni.cz/udpipe ) erzeugt.
Schön und gut, aber was habe ich von diesen aufbereiteten Daten?
Getreu dem Sprichwort „Sprache ist der Schlüssel zur Welt“ von Wilhelm von Humboldt können wir über das gesprochene oder geschriebene Wort hinaus tiefgehende Schlussfolgerungen ziehen. Jeder Kunde und Mitarbeiter hinterlässt mit seinen verfassten Texten Datenspuren. Diese können uns auch nicht beschriebene Informationen wiedergeben. Anhand der Wortwahl und des Schreibstils ist man unter anderem in der Lage, auf die persönlichen Merkmale des Schreibers zu schließen. Ist er eher extrovertiert oder introvertiert? Was sind seine Bedürfnisse? Wie ist seine Persönlichkeit? (siehe auch https://personality-insights-demo.ng.bluemix.net/ )
Es lassen sich aber nicht nur Informationen und Schlussfolgerungen aus einzelnen Dokumenten ziehen. Mit Text-Mining-Methoden können ganze Dokumentenstapel verarbeitet werden. So lassen sich Dokumente automatisiert verschlagworten, Themenkomplexe identifizieren, Themen- bzw. Wortzusammenhänge ermitteln oder auch inhaltlich zusammenfassen. Oft können dabei wieder Methoden aus dem Bereich Machine Learning die Analysen unterstützen.
Der Umgang mit großen Datenbeständen ist in den letzten Jahren essenzielle Voraussetzung für eine erfolgreiche digitale Transformation hin zum datengetriebenen Versicherer geworden. Sich mit Big Data und der Verarbeitung der Daten zu beschäftigen, ist für die Assekuranz zur Pflichtaufgabe geworden.
