MLOps: Wie Versicherer ihre KI effizient betreiben
Versicherer können den Wirkungsgrad bei der Dunkelverarbeitung, Fraud Detection oder Next-Best-Offer-Methode durch den Einsatz von KI steigern. Das effiziente Betreiben der KI ist dabei wesentlich für den Erfolg. Im Beitrag möchten wir zeigen, wie dies mit dem MLOps-Ansatz gelingen kann.

Wenn es darum geht, einen Schadenfall zu bearbeiten, gehen Versicherer teilweise noch traditionell vor: Eingereichte Dokumente identifiziert und klassifiziert ein Angestellter dabei meist per Hand. Eine automatisierte Lösung würde nicht nur die Effizienz steigern, sondern zudem die Aufmerksamkeit der Mitarbeiter auf komplexere Fälle lenken. In einem weiteren Schritt der Schadenbearbeitung werden Betrugsfälle identifiziert. Fraud Detection Software, die auf Grundlage gesammelter Daten Betrugswahrscheinlichkeiten ermittelt, kann hier nutzbringend eingesetzt werden. Würde dann ein paar Wochen später noch eine automatisch generierte Next-Best-Offer den Kunden ansprechen, wären alle Beteiligten glücklich. An all diesen datengetriebenen Lösungen wird im Markt gearbeitet. Im wirklich effizienten Einsatz sind sie nur in den seltensten Fällen. Für Versicherer also die Chance, sich in einem Markt zu differenzieren, in dem die meisten Tarifinhalte und Services für die wichtigsten Produkte zunehmend identisch sind.
Die Schwierigkeiten des Machine-Learning-Betriebs
Für einen optimierten Einsatz müssen Daten sinnvoll und vor allem intelligent genutzt werden. Um eine größere Menge an Informationen zu verarbeiten und standardisierte Geschäftsvorfälle schneller abzuhandeln, kann die Arbeit von einer KI-Software übernommen werden – genauer gesagt von Machine Learning (ML). Die Software ist mit dieser Methode fähig, Wissen aus gesammelten Daten zu generieren. ML verwandelt beispielsweise nicht nur unstrukturierte Daten in strukturierte, sondern kann auf Basis dieser Daten automatisierte und durchaus komplexe Entscheidungen treffen: Zum Beispiel in der Schadenabwicklung oder der Analyse von Betrugstatbeständen können so möglichst präzise Ergebnisse generiert werden. Auch beim Pricing oder der individuellen Produktgestaltung ist die Anwendung denkbar.
Die Vorteile für Versicherungsunternehmen liegen auf der Hand: Die automatisierten Prozesse sparen Ressourcen, laufen schneller und sind weniger fehleranfällig. Was in der Theorie so einfach klingt, ist in der Praxis eine enorme Herausforderung. Schon der Betrieb von alltäglicher Software (Code) ist für Versicherer anspruchsvoll. Beim Machine Learning erhöht sich der Komplexitätsgrad noch durch zwei zusätzliche Komponenten: Daten (Data) bilden die Entscheidungsgrundlage eines Modells (Model), welches wiederum die in den Daten gefundenen Muster zur Ergebnisfindung heranzieht. Auf beide muss stets ein waches Auge geworfen werden: Zum Beispiel können sich Daten und deren zugrundeliegende Verteilung rasch ändern und somit die Leistung des Modells verringern (Model Decay). Ohne durchdachtes Konzept ist eine vernünftige Überwachung von Model Decay und anderen Effekten undenkbar. Ein leistungsstarkes ML-System lässt sich so unmöglich betreiben.
Die „optimale Lösung“: MLOps
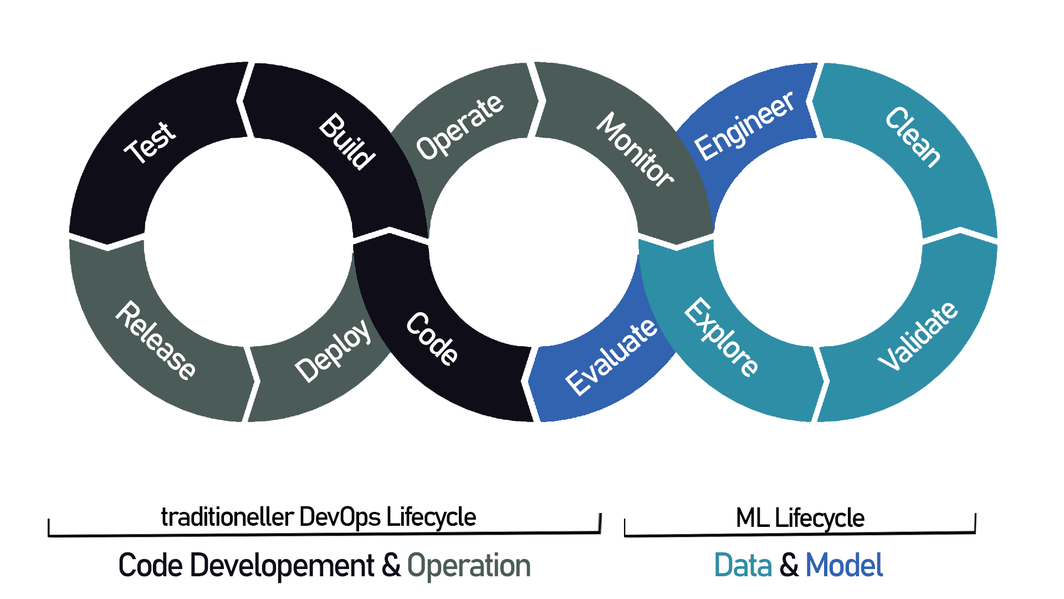
Doch das Konzept für einen solchen Betrieb existiert. ML-Systeme lassen sich mittels strukturierter Herangehensweise betreiben, die das entsprechende Mindset, die passenden Methoden und die richtigen Werkzeuge verbindet. All das vereint der MLOps-Ansatz, der die Grundgedanken von DevOps weiterführt. DevOps hat sich in der modernen IT bereits als gut funktionierende Methode etabliert. Dabei verschmelzen der Lifecycle der Entwicklung (Development) und des Betriebs (Operation), wobei gleichzeitig versucht wird, so viel wie möglich zu automatisieren.
MLOps erweitert den DevOps-Ansatz um die Anforderungen an ein ML-System. Der MLOps-Ansatz bezieht die zusätzlichen ML-Komponenten Daten und Modell von Anfang an in Entwicklung und Betrieb mit ein. Dabei werden Daten regelmäßig gesammelt (Monitor), validiert (Validate) und bereinigt (Clean). Gleichzeitig nimmt MLOps das Modell mit auf, welches eines ständigen Trainings, Tunings (Engineer) und fortlaufender Überprüfung (Evaluate) bedarf. MLOps etabliert also einen kontinuierlichen Prozess, der die Stabilität des Systems gewährleistet und versucht, Model Decay und weiteren Effekten effizient zu begegnen. Dabei hängt die operative Umsetzung stark von Erfahrungen und Voraussetzungen der Unternehmen ab. Etablierte DevOps bieten zwar eine solide Grundlage, müssen aber erweitert werden.
Zukunftsorientiert am Markt platzieren
Also: Veraltete oder langsame Prozesse können für Versicherer mit ML veredelt werden. Sie ermöglichen ganz neue Anwendungen und eine Chance, sich vom Rest des Marktes abzuheben. Für einen Einstieg ist es dabei nicht zu spät! Ein waches Auge auf die relevanten Use Cases für Machine Learning und proaktive, frühzeitige Weiterentwicklung der operativen IT-Prozesse zur Vorbereitung auf MLOps liefern eine gesunde Grundlage, um als First Follower Profit aus den Erfahrungen der Tech Giganten und einiger fortschrittlicher Finanz- und Versicherungskonzerne zu schlagen. Eine Differenzierung am Markt durch eine datengetriebene Prozess- und Produktlandschaft wird so möglich. Noch ist kein Standard der relevanten Methoden und Werkzeuge für MLOps definiert, wodurch ein individuelles Vorgehen auf Basis der bestehenden Betriebsprozesse und ersten Erfahrungen am Markt notwendig ist. Die ersten Versuche der Versicherer mit ML zeigen: Wer erfolgreiche Prototypen aus dem Pilotstatus wirklich in den laufenden Betrieb bringen möchte, muss sich zeitnah mit MLOps auseinandersetzen. Andernfalls ist es sehr wahrscheinlich, dass diese Anstrengungen als „ewige Piloten“ verharren und eine relevante (wenn auch anspruchsvolle) Zukunftstechnologie diskreditieren.
Digitales Innovationslabor: KI und Machine Learning in Versicherungsunternehmen
In einer Workshop-Reihe widmen wir uns den Zukunftsthemen künstliche Intelligenz und Machine Learning. Startschuss für das Innovationslabor war der 22. April 2021. Aufgrund der hohen Nachfrage planen wir eine weitere Workshop-Reihe. Gern setzen wir Sie auf eine Interessentenliste und melden uns bei Ihnen, sobald weitere Termine feststehen. Schreiben Sie gern an susan.drechsler@versicherungsforen.net.









